AI for Tax-Efficient Investing: From Clever Hacks to a Real System

When you’re a millennial techie or a founder, “tax efficiency” in your personal finance stops being about picking a muni fund and calling it a day.
You’re juggling:
- W-2 income + RSUs and options
- Multiple brokerage accounts and fund products
- Private deals (oil & gas, real estate, venture) that come with 100-page PPMs and nasty K-1 surprises
- Rapidly changing tax rules that heavily bias certain structures over others
That is not a spreadsheet problem. It’s a data + modeling + systems problem.
In this piece, we’ll outline how I think about an AI-native stack for tax-efficient investing, in three layers:
- LLM layer - turn messy documents and tax rules into structured, comparable features.
- Forecasting layer - non-LLM models that predict the economic drivers (e.g., oil prices, cash flows) and simulate after-tax outcomes.
- User context layer - quantify how “sensible” a strategy is for this specific human, not for an abstract investor.
You can think of it as building a feature store for tax alpha, and then using classic ML on top.
1. Layer 1 – LLMs as a feature engine for tax strategies
The raw inputs to tax-efficient investing are brutally unstructured:
- IRS publications and audit guides
- Statutes and bills (e.g., energy tax provisions, QBI rules, NIIT, at-risk rules)
- Oil & gas partnership PPMs, private placement memos, operating agreements
- ETF/fund prospectuses and statements of additional information
- Municipal bond offering docs
- Client tax returns, brokerage statements, equity grant docs
Historically, humans skim these, pull out a few rules of thumb, and then operate on heuristics.
What LLMs bring to the table
Recent work shows GPT-class models can perform financial statement analysis and even predict earnings changes from anonymized financials better than sell-side analysts in some setups. LLMs have also been used to estimate “core earnings” from bloated disclosures and reconcile recurring vs non-recurring items at scale. Separate research shows they’re increasingly capable at extracting and interpreting structured data from financial tables in PDFs , something that’s been a pain point for years.
That’s exactly the skillset you want for tax strategy work.
Concretely, the LLM layer’s job is to convert documents into features:
- From an oil & gas PPM + subscription docs:
- Deal size, capital call schedule, minimum ticket
- % of expenditures that qualify as intangible drilling costs (IDCs) (currently deductible) vs tangible costs (capitalizable)
- Expected production curve and payout waterfall
- Sponsor fees, carried interest, GP/LP alignment
- Whether losses are likely to be passive/active, how they interact with §469
- Deal size, capital call schedule, minimum ticket
- From IRS material & current law:
- Which expenses are deductible in year one, which are amortized (e.g., 65-80% of many direct oil & gas investments is often deductible as IDCs in the year of investment, subject to limits).
- Interactions with QBI, NIIT, AMT, at-risk rules, etc.
- New incentives like 100% expensing or enhanced depreciation under recent energy bills.
- Which expenses are deductible in year one, which are amortized (e.g., 65-80% of many direct oil & gas investments is often deductible as IDCs in the year of investment, subject to limits).
- From fund / ETF docs:
- Turnover expectations, distribution policy (ordinary vs qualified dividends), likelihood of capital gain distributions
- Structural tax traits: ETF in-kind redemptions vs mutual fund, muni vs taxable, state-specific exemptions
- Turnover expectations, distribution policy (ordinary vs qualified dividends), likelihood of capital gain distributions
- From client docs (with explicit consent):
- Historical realized gains/losses, carryforwards
- Current portfolio turnover and yield
- Employer equity grant terms, vesting calendars, 83(b)/ISO/NSO nuances
- Historical realized gains/losses, carryforwards
Architecture: how this actually looks
At infra level, this layer is:
- A document ingestion pipeline (PDF, HTML, scans → OCR → layout model).
- A RAG system over tax law, IRS publications, and sponsor docs.
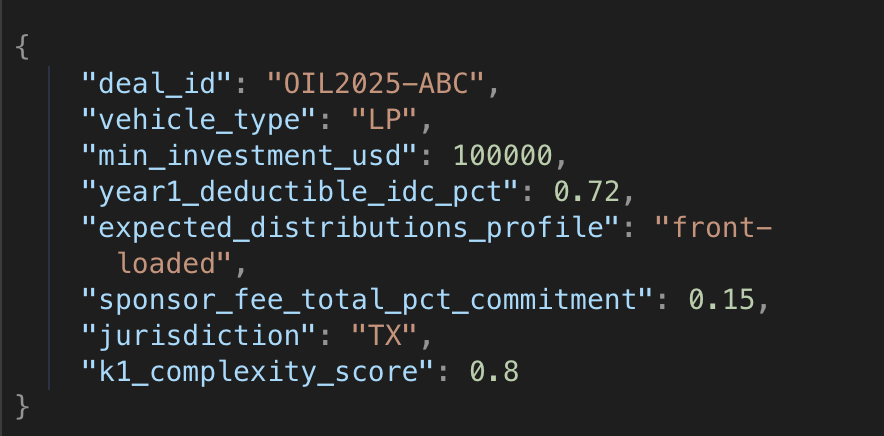
- A set of schema-constrained LLM extractors that output JSON with fields like:
- A feature store that accumulates these across hundreds or thousands of offerings.
Key points for a serious setup:
- No raw LLM “chat answers” anywhere near the decision surface. You’re using LLMs as parsers and annotators, not as oracles.
- Heavy reliance on validation: regex/logic checks, cross-doc consistency, sampling to humans, and regression tests when you upgrade models.
- Explicit versioning of extracted features so you can reproduce what the system believed when a recommendation was made.
This is your “Layer 1”: a continuously updated, queriable representation of the tax-relevant universe.
2. Layer 2 - Forecasting the economics, not just the tax
A tax benefit is only worth chasing if the underlying economics don’t blow up.
That’s where classical ML and time-series models come in.
Example: Oil & gas as a tax-efficient strategy
Direct oil & gas investments are often pitched to high-income investors because:
- IDCs are generally immediately deductible (often 65–80% of the investment in year one).
- You may also get depletion allowances and accelerated depreciation.
Recent U.S. legislation (e.g., the 2025 “OBBB” energy bill) has doubled down on expensing and favorable treatment for certain domestic production assets, while scaling back some clean-energy credits.
On paper, you can generate very high “tax alpha” in year one. In practice, this only matters if:
- The project’s oil/gas production is within reasonable ranges.
- Commodity prices don’t sit at the wrong tail of the distribution for too long.
- Sponsor behavior and cost discipline are sane.
So you need a forward-looking distribution of returns.
What the forecasting layer does
This layer consumes:
- Macro & factor histories: WTI/Brent prices, gas prices, basis differentials, rate curves.
- Micro features extracted by the LLM layer: cost structure, production expectations, leverage terms.
- Market regimes & structural breaks.
State-of-the-art models for crude oil forecasting increasingly use hybrid architectures:
- LSTM and GRU models to capture nonlinear dynamics and long memory.
- Combined with GARCH-type models to handle volatility clustering and regime shifts.
Empirical work shows these LSTM/GARCH-LSTM hybrids can outperform vanilla ARIMA and simple neural nets on oil price prediction across several horizons.
For a wealth platform, the goal is not “get oil price exactly right”. The goal is:
- Generate a realistic scenario set for prices and production (Monte Carlo).
- Combine that with capital stack terms to produce a distribution of pre-tax IRR and loss probabilities.
- Feed that into a tax-aware optimization layer.
From pre-tax to after-tax: tax-aware optimization
There’s a growing line of work on integrating ML forecasts with tax-sensitive portfolio optimization. One recent framework explicitly proposes a two-layer architecture: predictive models on the front, then an optimization step that maximizes expected utility after accounting for tax rules and frictions.
More broadly, AI in portfolio management is already used to:
- Pre-select assets based on return predictability.
- Optimize allocations under complex constraints (risk, liquidity, ESG, etc.).
You extend this by:
- Modeling realized tax outcomes: short vs long-term gains, distributions, K-1 loss usability, state taxes.
- Including tax-loss harvesting and asset location mechanics (place high-yield assets in tax-advantaged accounts, use munis in taxable, etc.). Robo-advisors already do daily TLH with algorithms around drift thresholds and wash-sale rules.
The output isn’t just an expected pre-tax IRR; it’s something like:
- Distribution of after-tax IRR
- Expected tax benefit (e.g., present value of deductions)
- Tail loss metrics after tax (e.g., 5% worst-case after-tax outcome)
That’s what you need to compare an oil & gas partnership vs, say, a muni ladder vs simply increasing your TLH aggressiveness in a broad equity portfolio.
3. Layer 3 – User context and “how much sense” this makes
Two HNIs with identical income can have completely different tax strategy answers.
This layer is about quantifying fit, not just theoretical tax alpha.
First-class features about the human
For each user, you want a rich, structured profile:
- Tax position
- Federal + state brackets, NIIT applicability
- AMT exposure
- Capital gain/loss carryforwards
- Passive vs non-passive income, QBI eligibility
- Federal + state brackets, NIIT applicability
- Balance sheet and flows
- Concentration in employer equity
- Liquidity needs (upcoming home/education, potential exit)
- Debt structure (mortgage, margin, private credit)
- Concentration in employer equity
- Behavior & preferences
- Historical realized risk tolerance (drawdown behavior, not survey answers)
- Tolerance for K-1s, illiquidity, and complexity
- Preferences around ESG / fossil fuels, which matter for anything oil & gas
- Historical realized risk tolerance (drawdown behavior, not survey answers)
- Jurisdictional / entity structure
- State of residence(s), cross-border exposure
- Use of LLCs, LPs, S-corps for operating businesses and investments
- State of residence(s), cross-border exposure
This is classic feature engineering, just on a human.
A “fitness score” for each tax strategy
Given a candidate strategy ( S ) (e.g., “$250k into 2025 O&G LP X”, “$500k CA muni ladder”, “upgrade TLH to direct-indexing”), you can define:
Then define a fit score:
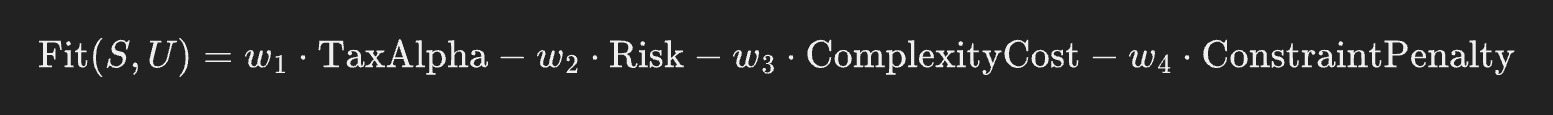
The “Layer 3” job is to learn or calibrate these ( w_i ) for each user over time:
- Use bandit / RL-style updates based on what recommendations they accept, decline, or reverse.
- Incorporate feedback loops: “never show me fossil deals again”, “I’m fine filing extra forms if expected gain is >$X”.
- Respect hard constraints that are policy or compliance-driven, not model-driven.
This is how you “quantify the amount of sense” a tax strategy makes for a specific infra/ML engineer in California with $4M of concentrated tech equity vs a founder in Texas with pass-through income and different state rules.
4. Putting the three layers together: an AI-native tax engine
If you’re thinking in systems terms, the full stack looks like:
- Data & ingestion
- Connect custodians, 401(k), equity admin systems, payroll, existing CPAs.
- Ingest public and private deal docs, tax law updates, IRS materials.
- Normalize into a unified, versioned data lake.
- Connect custodians, 401(k), equity admin systems, payroll, existing CPAs.
- Layer 1 – LLM feature extraction
- RAG + schema-constrained extraction for all strategy docs.
- Store into a feature store keyed by security/deal/strategy ID.
- Maintain gold datasets and continuous evaluation for extraction performance.
- RAG + schema-constrained extraction for all strategy docs.
- Layer 2 – Forecasting & optimization
- Time-series ML for key drivers (oil prices, rates, credit spreads, equity factors).
- Scenario generation and Monte Carlo on project-level and portfolio-level outcomes.
- Tax-aware optimization: tax-loss harvesting, asset location, and cross-strategy comparisons.
- Time-series ML for key drivers (oil prices, rates, credit spreads, equity factors).
- Layer 3 – User context & policy
- User-level feature store (tax, balance sheet, behavior, constraints).
- Fit scoring for each candidate tax strategy.
- Ranking and selection under constraints; generate explanations (“This reduces 2025 taxable income by ~$X at Y% confidence, but ties up $Z in illiquid assets with A–B risk characteristics.”).
- User-level feature store (tax, balance sheet, behavior, constraints).
- Interface & governance
- Surfaced as “next best actions”:
- “Harvest losses in these tickers today; swap to these equivalents.”
- “You’re a candidate for a $200k O&G IDC deal; expected 2025 deduction ~$140k, but here’s the risk profile.”
- “Move this high-yield credit fund into your rollover IRA; replace with tax-efficient equity in taxable.”
- “Harvest losses in these tickers today; swap to these equivalents.”
- Human advisor oversight, with clear audit trails showing:
- Which models and versions were used
- Which features and tax rules drove the recommendation
- What alternatives were considered and rejected
- Which models and versions were used
- Surfaced as “next best actions”:
This is beyond what today’s robo-advisors generally do, even though they already automate TLH and some tax optimization at scale.
5. Caveats and what you should not automate away
If you’re building or using such a system, there are non-negotiables:
- Legal & compliance boundaries
You’re operating inside securities and tax advice regimes. The AI stack can propose and simulate; ultimately, recommendations must be grounded in firm policy and reviewed by qualified professionals. - Regime risk
Tax law is political. Energy incentives can be reinforced (as with recent bills favoring domestic production) or attacked (ongoing debates about IDC deductions for large oil companies).
Your models must be re-run under alternative legal regimes; don’t treat today’s code as permanent. - Model risk and explainability
Any optimization that touches someone’s tax return needs to be explainable. It’s not enough that an LSTM-GARCH stack outperforms ARIMA in RMSE; you need to be able to articulate, at the user and regulator level, why you’re recommending a specific move, in human language, with traceable inputs. - Human factors
Many “optimal” strategies die on contact with real behavior: people don’t wire $250k into an illiquid LP because a model says so if they can’t sleep at night.
The goal isn’t to replace human judgment. It’s to surface the right set of options, with quantified trade-offs, at the right time, in a world where the search space is far too large for any human team to brute force.
Closing thought
If your tax situation is complex enough that “buy VT, tax-loss harvest once a year” probably leaves real money on the table. The interesting problem isn’t “can AI pick better stocks?”, it’s:
Can we build a system that continuously ingests the tax code, real-world deal structures, market dynamics, and your actual life constraints, and then proposes high-conviction, explainable tax-efficient actions?
That’s an AI/ML problem worth solving: not just for incremental returns, but for turning a messy, opaque part of wealth into something tractable, auditable, and genuinely intelligent.
PS: We'll go over the practical applications of these models in our upcoming webinar and QnA session. If you're a ML engineer, interested in brainstorming more, register here. Use code ALPHAREFER for a complimentary ticket.

Plan with an expert
What to expect




.png)
.jpg)
.png)
.png)